Towards New Speeds
In this post, I hope to illustrate how GPU's actually accelerate parallel operations
Let’s get started
Firstly, how do GPU’s really work? Well, at a lower level, the architecture looks something like this…
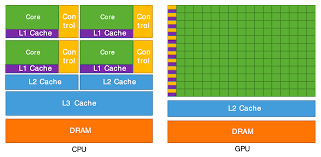
Focus on the differences between the two, CPUs have few, very highly specialised and refined cores. GPUs on the other hand have hundreds of more primitive, yet powerful cores.
This is the reason why GPUs can’t do I/O and stuff, its because they are meant solely for mathematical operations.
But what’s the point of so many cores??
This is where SIMD or Single Instruction Multiple Data processing comes in handy. See, many operations(image and volume ones notoriously) are extremely taxing for the CPU to perform. Imagine being part of a team of 8/16 people, stamping a sheet of paper, except you have 10^6 sheets to stamp. Even if you took 1 ms/sheet, it would still take you insanely long to finish your jobs. And I mean, you have better things to do right?
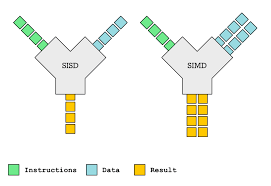
Well what if you could hire 10^3 people for cheap and give each of them a sheet of paper to stamp? Wouldn’t that greatly speed things up? This is the core idea behind SIMD processing, you have an operation that is to be done thousands of times, over and over again, just on different data.
So you give each GPU core a part of the data and let it do the job, since the GPU has so many cores, it’s not really a problem.
So whats the catch?
Continuing the stamping sheet analogy, giving the sheets to 10^3 workers is challenging and time-consuming. In other words, data transfer is a problem, since GPU VRAM is separate from CPU RAM
Additionally, parallel programming forces you to think in an additional dimension, because your code is being executed 100s of times at the same time. This makes writing efficient kernels difficult, since branching is frowned on at the GPU, and you need some way of preventing data races.
That is to say nothing of the increased power consumption and high cost of hardware.
Despite all of this however, GPUs are still heavily favoured, because the speed-up they offer greatly outweights the rest.
Well, how do I use my GPU?
Let’s take an example, hopefully youre already familiar with image convolution. If not, the image below explains it well
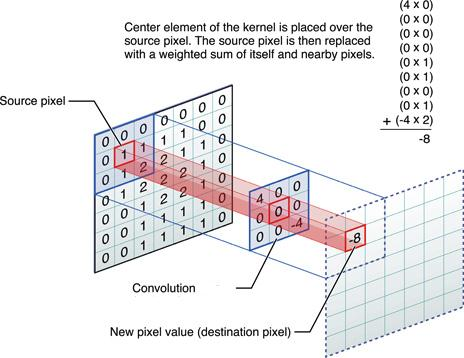
For each iteration, we center the kernel over a pixel, multiply the overlapping values, add them up and then (optionally)divide by sum of kernel values. On CPU? For an m x n image and a k x k kernel, this is an O(mn * k^2) operation, meaning the time taken for convolution for a given data size increases tremendously.
This can be greatly lessened using a GPU.
But for that, we need to first identify the stamping task here, the tedious computation which is easy to do, but time consuming.
Image Convolution
If you thought of the matmul operation happening at each pixel, you’d be correct! This is one of the easiest ways to parallelise convolution. We’re repeatedly performing matrix multiplication, with different pixels at the center each time
Therefore SIMD can be applied here, the instruction being matmul and the data being all the pixels.
On a lower level, this is represented by the diffferent thread_id given to each thread on the GPU. This id represents a one to one mapping of an integer to input data elements.
Incase of Images, it is the pixel number that is at the center.
Here’s an example of how convolution can be parallelized, note that this is not the most efficient and is nowhere near perfect, but it is simple enough to understand.
__kernel void
convolution(
__global float *image_array, __global size_t *image_dsize,
__global float *kernell_array, __global size_t *kernell_dsize,
__global float *output) {
/* get the image and kernel size */
int image_height = image_dsize[0];
int image_width = image_dsize[1];
int kernell_height = kernell_dsize[0];
int kernell_width = kernell_dsize[1];
/* get the local group id */
int id = get_global_id(0);
int row = id / image_width;
int col = id % image_width;
if (row < image_height && col < image_width) {
float sum = 0;
/* matmul operation as normal*/
for (int y = -kernell_height / 2; y <= kernell_height / 2; y++) {
for (int x = -kernell_width / 2; x <= kernell_width / 2; x++) {
if (row + y >= 0 && row + y < image_height && col + x >= 0 &&
col + x < image_width) {
sum += (image_array[(row + y) * image_width + col + x] *
kernell_array[(y + kernell_height / 2) * kernell_width + x +
kernell_width / 2]);
}
}
}
output[row * image_width + col] = sum;
}
}
A new outlook
Of course, the world would be a lovely place if everything could be parallelised as easily as this. Realistically, parallelizing these operations is hard, but you have tools like local groups, barriers, etc to help you out!