Seeking Fast at Any Point in a BZ2 Compressed File
Hey everyone welcome to the second episode of my Google Summer of Code project series, where I’m working on partial decompression for large datasets.
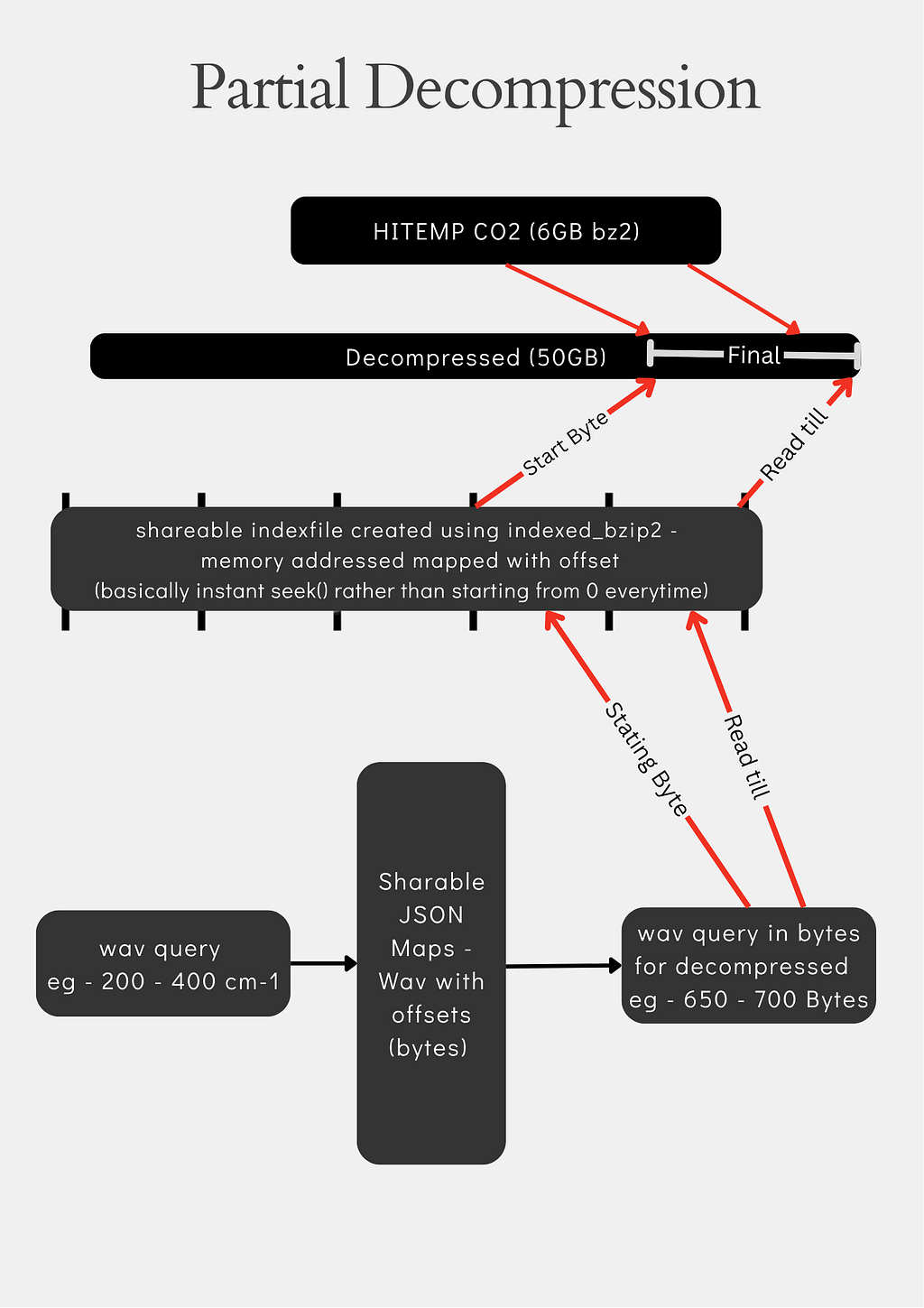
So, what’s the big catch here? Well, the CO₂ dataset I’m working with is about 6 GB in its compressed .bz2form, and when you decompress it, it explodes into 50 GB. Most systems struggle to load that much data into memory or parse it into a DataFrame, either due to storage limits, memory, or swap issues.
And obviously not everyone wants the whole 50 GB anyway. Usually, people need just a 1 GB chunk from somewhere inside. So decompressing the entire thing just to fetch a small part is a massive waste of time and resources.
That’s where I built a pretty clever mechanism to handle this, saving both storage and a whole lot of time. Here’s how it works:
The Problem with Seeking in bz2 If a user wants to randomly seek to any point in a decompressed stream (without decompressing the whole thing), technically you can, but there’s a catch bz2 doesn’t support random access. Even if you run something like: `f.seek(1024*1024*1024)` to jump to the 1 GB mark, under the hood, it still has to decompress from the start up to that point. Which means a lot of wasted time.
The Trick is Memory Mapping and Indexing, Here’s where the first optimization comes in that is memory mapping the decompressed byte offsets to the corresponding compressed byte positions. It’s a one-time cost for us maintainers. We generate this mapping and share an index file with users. Thankfully, there’s already a package called indexed_bzip2 that can seek to a compressed offset directly practically instantly.
But users aren’t going to query in bytes. They’ll request data based on something meaningful in this case, wavenumber (in cm⁻¹).
So I created another mapping: from wavenumber to the corresponding decompressed byte offset. When a user queries for a wavenumber, it first maps to the decompressed offset, and from there to the memory offset using the indexed_bzip2 mapping we created earlier. This mapping is built at intervals of 500 MB essentially creating fixed virtual blocks in the decompressed stream.
If a user requests a wavenumber lower than a known value, it finds the largest known offset smaller than the current wavenumber. For a higher wavenumber, it finds the lower bound in the mapping. I finally got to use binary search in a real project for this lookup and it makes the lookup super fast.
Keeping fixed-size blocks also makes it easier to maintain a caching mechanism later. If we had arbitrary block sizes, caching would be a pain. But with fixed 500 MB chunks, we can decompress extra blocks and combine them as needed, without overcomplicating the system.
In the next episode, I’ll share some real benchmarks on how much time and storage this optimization saves. It’s been a fun problem to solve and finally a chance to use a binary search outside of textbook problems, stay tuned for the next episode ;)