Building a super-fast SIMD parser for dataset - The final episode
Welcome to the last episode of my Google Summer of Code series. In the previous post I showed how I could seek inside a large .bz2 file and decompress a region to get about 500 megabytes of raw data. That worked, but it still required downloading the full 6 gigabyte compressed file up front. After talking with the maintainers we switched to a partial-download approach: a user requests a region and the system downloads only the 45–65 megabytes of compressed bytes that decompress to the exact 500 megabyte window we need. That change took some extra work, but it makes the system feel immediate for new users, you can get hundreds of thousands of parsed rows in a couple of minutes without pulling the whole archive.
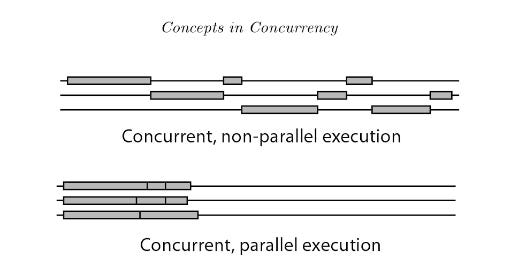
When building a parser that aims to beat Pandas’ vectorized operations, single-threaded concurrency isn’t enough. Concurrency is about handling multiple tasks by rapidly switching between them on a single core. It gives the illusion of things happening in parallel, but at any given instant only one task is actually running. That’s why it feels like multitasking in everyday life where you’re switching back and forth, but you’re not truly doing two things at the same time.
True parallelism, on the other hand, is about dividing independent work across multiple cores so that tasks literally run simultaneously. Each task makes progress without waiting for others to finish, which is what makes SIMD vectorization or multiprocessing so powerful for workloads like parsing large datasets.
Because each record is fixed-width (161 characters), HITEMP files are perfect for vectorized parsing. That predictability is everything. When you line up multiple records in memory, the same byte offset across records becomes the same lane in a vector register. You can then scan, trim, and classify with a handful of SIMD instructions instead of dozens or hundreds of scalar comparisons.
I wrote the parser in modern C++ for x86_64 using AVX2 intrinsics and OpenMP. The SIMD parts target Intel and AMD; an ARM port would need a NEON implementation.
Below is the field layout, based on the HITRAN 2024 format, showing start and end indices plus a short description for each 161-byte record.

The basic SIMD idea I used is to process eight records at once. The magic constants are HITRAN_LINE_LENGTH = 161 and SIMD_WIDTH = 8. By arranging eight consecutive 161-byte records so that corresponding bytes are contiguous across lanes, an AVX2 load gives you the same byte position for records 0 through 7 in one register. Most of the heavy work, classification and trimming, happens with vector instructions. Numeric conversion of the small trimmed substrings then happens in short scalar routines. This hybrid approach is both robust and fast.
// Check 32 bytes at once for ASCII digits using AVX2
#include <immintrin.h>
static inline __m256i simd_is_digit(const __m256i chars) {
const __m256i char_0 = _mm256_set1_epi8('0');
const __m256i char_9 = _mm256_set1_epi8('9');
// ge_0: chars >= '0' (compare chars > '0' - 1)
const __m256i ge_0 = _mm256_cmpgt_epi8(chars, _mm256_sub_epi8(char_0, _mm256_set1_epi8(1)));
// le_9: chars <= '9' (compare '9' + 1 > chars)
const __m256i le_9 = _mm256_cmpgt_epi8(_mm256_add_epi8(char_9, _mm256_set1_epi8(1)), chars);
return _mm256_and_si256(ge_0, le_9);
}
Trimming trailing spaces in a fixed-width field is another primitive I rely on. I load 16 bytes into an SSE register, compare them to ' ' to get equality lanes, then build a mask with _mm_movemask_epi8 and use builtin bit operations to locate the first or last non-space. That single short vector sequence replaces up to 16 scalar checks, which turns into a surprisingly big win in the hot path same result, far fewer instructions.
// Find last non-space within a 16-byte tail using SSE
#include <emmintrin.h>
#include <tmmintrin.h> // optional, depending on intrinsics used
int find_last_non_space_16(const char *ptr16) {
__m128i chars = _mm_loadu_si128(reinterpret_cast<const __m128i*>(ptr16));
__m128i spaces = _mm_set1_epi8(' ');
// cmp -> 0xFF bytes where char == ' '
__m128i eq = _mm_cmpeq_epi8(chars, spaces);
// invert: 0xFF where not space
__m128i not_spaces = _mm_andnot_si128(eq, _mm_set1_epi8(0xFF));
int mask = _mm_movemask_epi8(not_spaces); // 16-bit mask
if (mask == 0) return -1; // all spaces
// position of highest set bit (0..15)
int last = 31 - __builtin_clz(mask);
return last;
}
For numeric fields, I use SIMD to quickly find the start and end of the number, then pass that small trimmed piece to a simple scalar routine that turns it into a double. Fully vectorizing a stod-style conversion isn’t worth it the fields are short, and the real heavy work is in trimming and classification. Once that’s done, converting to a number is fast, so this mix of SIMD for finding bounds and scalar for conversion works best.
// Example: trim and parse a scientific notation field
double parse_scientific_field(const char *field_start, int width) {
// find first non-space
int start = 0;
while (start < width && field_start[start] == ' ') ++start;
// find last non-space roughly using the 16-byte helper for the tail
int end = width - 1;
int tail_check_start = std::max(0, width - 16);
int tail_last = find_last_non_space_16(field_start + tail_check_start);
if (tail_last >= 0) end = tail_check_start + tail_last;
// now convert substring field_start[start..end] to double (scalar)
if (start > end) return 0.0; // empty field
// lightweight manual parser or call fast custom atof
std::string_view s(field_start + start, end - start + 1);
return fast_atof(s); // implement a small, robust parser for "d.dddE[+-]dd"
}
The top-level loop streams decompressed data in fixed-size windows, groups lines into batches, and processes each batch with OpenMP. Streaming keeps peak RAM small, and writing results incrementally to binary files avoids building huge in-memory structures. This lets the parser handle large slices without ballooning memory and makes it easy to flush partial results to disk while the rest is still being parsed think of it as eating the dataset in bite-sized chunks instead of trying to swallow the whole buffet at once.
// High-level streaming + batching
constexpr size_t CHUNK_DECOMPRESSED = 500ULL * 1024 * 1024; // 500 MB
constexpr int LINES_BATCH = 100000; // tune to memory and CPU
std::vector<std::string> lines;
lines.reserve(LINES_BATCH);
while (read_next_decompressed_chunk(chunk_buffer)) {
std::istringstream ss(chunk_buffer);
std::string line;
while (std::getline(ss, line)) {
if (line.size() >= HITRAN_LINE_LENGTH) {
// ensure exact length by padding or truncating
if (line.size() > HITRAN_LINE_LENGTH) line.resize(HITRAN_LINE_LENGTH);
else if (line.size() < HITRAN_LINE_LENGTH) line.append(HITRAN_LINE_LENGTH - line.size(), ' ');
lines.push_back(std::move(line));
if (lines.size() >= LINES_BATCH) {
process_lines_simd_openmp(lines);
flush_binary_outputs();
lines.clear();
lines.reserve(LINES_BATCH);
}
}
}
}
// process any leftover lines
if (!lines.empty()) {
process_lines_simd_openmp(lines);
flush_binary_outputs();
lines.clear();
}
The process_lines_simd_openmp function rearranges memory into a SIMD-friendly layout, pads shorter lines with spaces, and then runs an OpenMP parallel loop over SIMD-sized batches. I use alignas(32) for working buffers and #pragma omp for schedule(dynamic, 1000) to avoid imbalance when some batches cost more to trim. Each thread works on its own local buffers, gathers up to SIMD_WIDTH records into lanes, runs AVX2 scans for classification and trimming, and then calls tight scalar converters for the trimmed substrings. Padding and predictable offsets keep the inner loop branch-free and fast, and thread-local outputs are flushed or merged with minimal contention.
// Simplified structure of batch processor
void process_lines_simd_openmp(const std::vector<std::string>& lines) {
const size_t records = lines.size();
const size_t batch_records = SIMD_WIDTH; // 8
const size_t batches = (records + batch_records - 1) / batch_records;
// prepare a contiguous buffer laid out so that byte i of all 8 records are contiguous
// allocate aligned working memory per thread if needed, or use a shared aligned buffer
// ...
#pragma omp parallel
{
// per-thread buffers and outputs
#pragma omp for schedule(dynamic, 1000)
for (size_t b = 0; b < batches; ++b) {
// gather up to SIMD_WIDTH records into vector lanes
// run AVX2 scans on lanes for digits, spaces, signs, decimal points, 'E', etc.
// call scalar converters for trimmed substrings
// append parsed values to thread-local output buffers
}
// thread-local writes to disk or atomic append to global writer
}
}
Memory layout and padding are absolutely critical here. I pad shorter lines with spaces so that every SIMD group has predictable offsets and alignment. This means the inner loop has no extra branches, and the SIMD lanes don’t get clogged with special-case logic. The flow is straightforward: let SIMD do the scanning, use in-register masks to quickly find offsets, and then hand things off to a small scalar routine for the actual conversion.
Because we now download compressed chunks that expand into exact 500 MB windows, caching becomes both simpler and more powerful. These decompressed windows are reproducible, so if a user requests data close to something we’ve already seen, we can serve parsed results directly from the cache. In practice this completely changes the onboarding experience from “download six gigabytes before you can even start” to “get results for the region you care about as fast as possible”.
So finally, after merging this pull requests, my Google Summer of Code project is complete. The project felt medium-sized at the start, but it turned into something much bigger than I expected I learned a ton over the last three months. Combining the partial-download + decompression approach with a super-fast SIMD parser took extra effort but it was worth it, new users can now get large parsed slices of the dataset quickly without downloading the whole archive.
Huge thanks to the maintainers for all their feedback and patience especially Dr. Nicolas Minesi and Dr. Dirk van den Bekerom. Their reviews pushed the code and design in the right direction. This is the final technical GSOC post in the series, and I’ll keep contributing and maintaining the project. Stay tuned for more blog posts soon. ;)