Handling Data over time
There’s a widespread trend in solar physics at the moment for correlation over actual science, so being able to handle data over time spans is a skill we all need to have. Python has ample support for this so lets have a look at what we can use.
Learning Objectives
- Understand and use Sunpy Time Series data.
- Create a pandas dataframe.
- Utilise the datetime package.
- Use the pandas dataframe to plot the data within it.
Sunpy Time Series
SunPy provides a timeseries object to handle this type of time series data. The module has a number of instruments associated with it, including:
- GOES XRS TimeSeries
- SDO EVE TimeSeries for level 0CS data
- Proba-2 LYRA TimeSeries
- NOAA Solar Cycle monthly indices.
- Nobeyama Radioheliograph Correlation TimeSeries.
- RHESSI X-ray Summary TimeSeries.
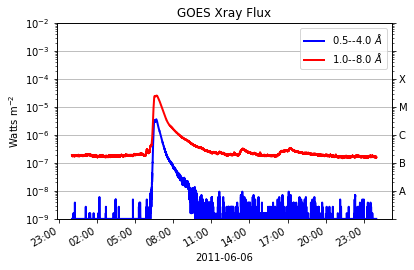
We’re going to examine the data created by a solar flare on June 7th 2011.
Lets begin with the import statements:
import numpy as np
import sunpy
import sunpy.data.sample
import sunpy.timeseries as ts
import matplotlib.pyplot as plt
%matplotlib inline
Now lets look at some test series data, in this case we can utilitse the sunpy sample data. Do this with import sunpy.data.sample
goes_ts = ts.TimeSeries(sunpy.data.sample.GOES_XRS_TIMESERIES, source='XRS')
Now goes data is a sunpy time seris object so we can inspect the object
goes_ts.meta
|-------------------------------------------------------------------------------------------------|
|TimeRange | Columns | Meta |
|-------------------------------------------------------------------------------------------------|
|2011-06-06 23:59:59.961999 | xrsa | simple: True |
| to | xrsb | bitpix: 8 |
|2011-06-07 23:59:57.631999 | | naxis: 0 |
| | | extend: True |
| | | date: 26/06/2012 |
| | | numext: 3 |
| | | telescop: GOES 15 |
| | | instrume: X-ray Detector |
| | | object: Sun |
| | | origin: SDAC/GSFC |
| | | ... |
|-------------------------------------------------------------------------------------------------|
NB: not all sources provide meta data so this may be empty.
The actual data is accessible tthrough the attributes of the timeseries object. Part of the advantage of using these inbuilt functions we can get a quicklook at our data using short commands:
goes_ts.peek()
Accessing and using the data
More custom plots can be made easily by accessing the data in the timeseries functionality. Both the time information and the data are contained within the timeseries.data code, which is a pandas dataframe. We can see what data is contained in the dataframe by finding which columns it contains and also asking what’s in the meta data:
goes_data = goes_ts.data
goes_data.columns
Index(['xrsa', 'xrsb'], dtype='object')
On Dictionaries
We can create keyword-data pairs to form a dictionary (shock horror) of values. In this case we have defined some strings and number to represent temperatures across europe
temps = {'Brussles': 9, 'London': 3, 'Barcelona': 13, 'Rome': 16}
temps['Rome']
16
We can also find out what keywords are associated with a given dictionary, In this case:
temps.keys() dict_keys(['London', 'Barcelona', 'Rome', 'Brussles'])
Dictionaries will crop up more and more often, typically as a part of differnt file structure such as ynl and json.
Pandas
In its own words Pandas is a Python package providing fast, flexible, and expressive data structures designed to make working with “relational” or “labeled” data both easy and intuitive. Pandas has two forms of structures, 1D series and 2D dataframe. It also has its own functions associated with it.
It is also amazing.
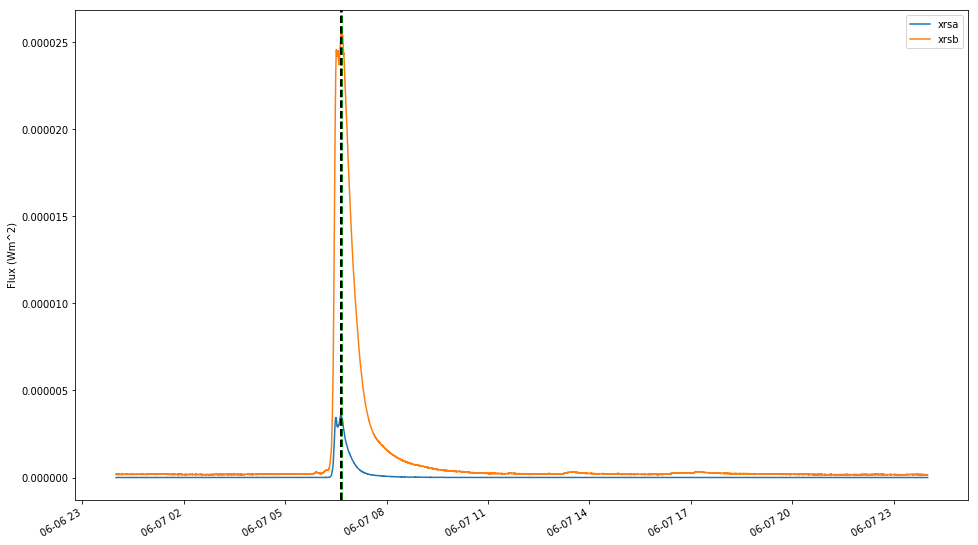
Timeseries uses these in built Pandas functions, so we can find out things like the maximum of curves:
# max time argument taken from long and short GOES channels
max_t_goes_long = goes_data['xrsb'].idxmax()
max_t_goes_short = goes_data.xrsa.idxmax()
print('GOES long : {}'.format(max_t_goes_long))
print('GOES short : {}'.format(max_t_goes_short))
GOES long : 2011-06-07 06:41:24.118999
GOES short : 2011-06-07 06:39:00.761999
So lets plot them on the graph
# create figure with raw curves
fig, ax = plt.subplots(figsize=(16,10))
goes_data.xrsa.plot(kind='line')
goes_data.xrsb.plot(kind='line')
plt.legend()
plt.ylabel('Flux (Wm^2)')
# max lines
plt.axvline(max_t_goes_long, color='green', linestyle='dashed',linewidth=2)
plt.axvline(max_t_goes_short, color='black', linestyle='dashed',linewidth=2)
<matplotlib.lines.Line2D at 0x7f981ed35c50>
Reading in Tablulated data
Now we have seen a little of what Pandas can do, lets read in some of our own data. In this case we are going to use data from Bennett et al. 2015, ApJ, a truly ground breaking work. Now the data we are reading in here is a structured Array.
data = np.genfromtxt('data/macrospicules.csv', skip_header=1, dtype=None, delimiter=',')
Now, the above line imports information on some solar features over a sample time period. Specifically we have, maximum length, lifetime and time at which they occured. Now if we type data[0] what will happen?
data[0]
(27.02261709, 13.6, b'2010-06-01T13:00:14.120000')
This is the first row of the array, containing the first element of our three properties. This particular example is a stuctured array, so the columns and rows can have properties and assign properties to the header. We can ask what the title of these columns is by using a dtype command:
data.dtype.names
('f0', 'f1', 'f2')
Unhelpful, so lets give them something more recognisable. We can use the docs to look up syntax and change the names of the column lables.
Google your troubles away
So the docs are here. Find the syntax to change to names to better to represent maximum length, lifetime and point in time which they occured.
data.dtype.names = ('max_len', 'ltime', 'sample_time')
DataFrame
Now a pandas DataFrame takes two arguments as a minimum, index and data. In this case the index will be our time within the sample and the maximum length and lifetime will be our data. So lets import pandas and use the dataframe:
Pandas reads a dictionary when we want to input multiple data columns. Therefore we need to make a dictionary of our data and read that into a pandas data frame. First we need to import pandas.
Dictionaries
So we covered dictionaries earlier. We can create keyword data pairs to form a dictionary (shock horror) of values. In this case
temps = {'Brussles': 9, 'London': 3, 'Barcelona': 13, 'Rome': 16}
temps['Rome']
16
We can also find out what keywords are associated with a given dictionary, In this case:
temps.keys() dict_keys(['London', 'Barcelona', 'Rome', 'Brussles'])
First, let’s import Pandas:
import pandas as pd
d = {'max_len': data['max_len'], 'ltime': data['ltime']}
df = pd.DataFrame(data=d, index=data['sample_time'])
print(df.head())
max_len ltime
b'2010-06-01T13:00:14.120000' 27.022617 13.600000
b'2010-06-01T12:58:02.120000' 36.208097 8.400000
b'2010-06-15T12:55:02.110000' 62.932898 24.199833
b'2010-07-07T12:23:50.110000' 38.970549 22.999667
b'2010-07-07T13:28:50.120000' 53.589420 21.799833
Datetime Objects
Notice that the time for the sample is in a strange format. It is a string containing the date in YYYY-MM-DD and time in HH-MM-SS-mmmmmm. These datetime objects have their own set of methods associated with them. Python appreciates that these are built this way and can use them for the indexing easily.
We can use this module to create date objects (representing just year, month, day). We can also get information about universal time, such as the time and date today.
NOTE: Datetime objects are NOT strings. They are objects which print out as strings.
import datetime
print(datetime.datetime.now())
print(datetime.datetime.utcnow())
lunchtime = datetime.time(12,30)
the_date = datetime.date(2005, 7, 14)
dinner = datetime.datetime.combine(the_date, lunchtime)
print("When is dinner? {}".format(dinner))
2018-09-06 18:17:45.411540
2018-09-06 17:17:45.411670
When is dinner? 2005-07-14 12:30:00
Looking back at when we discussed the first element of data, and the format of the time index was awkward to use so lets do something about that.
print(df.index[0])
b'2010-06-01T13:00:14.120000'
So this is a byte rather than a string so we’ll need to convert that using the string handling functionality in pandas
df['time'] = df.index.astype(str)
df.iloc[0].time
'2010-06-01T13:00:14.120000'
This is a string and python will just treat it as such. We need to use datetime to pick this string appart and change it into an oject we can use.
So we use the formatting commands to match up with the string we have.
dt_obj = datetime.datetime.strptime(df.iloc[0].time, '%Y-%m-%dT%H:%M:%S.%f')
print(dt_obj)
2010-06-01 13:00:14.120000
We can now get attributes from this such as the hour, month, second and so on
print(dt_obj.second)
print(dt_obj.month)
print(dt_obj.weekday())
14
6
1
Now the next logical step would be to make a for loop and iterate over the index and reassign it.
HOWEVER there is almost always a better way. And Pandas has a to_dateime() method that we can feed the time columns:
df['datetime'] = pd.to_datetime(df.time)
There is also one of the most powerful featues of python, Apply. Apply will take a function and apply it to all rows in a dataframe or column. The easiest way to do this is with a lambda function
df['other_datetime'] = df.time.apply(lambda x: datetime.datetime.strptime(x, '%Y-%m-%dT%H:%M:%S.%f'))
df.head()
| max_len | ltime | time | datetime | other_datetime | |
|---|---|---|---|---|---|
| b'2010-06-01T13:00:14.120000' | 27.022617 | 13.600000 | 2010-06-01T13:00:14.120000 | 2010-06-01 13:00:14.120 | 2010-06-01 13:00:14.120 |
| b'2010-06-01T12:58:02.120000' | 36.208097 | 8.400000 | 2010-06-01T12:58:02.120000 | 2010-06-01 12:58:02.120 | 2010-06-01 12:58:02.120 |
| b'2010-06-15T12:55:02.110000' | 62.932898 | 24.199833 | 2010-06-15T12:55:02.110000 | 2010-06-15 12:55:02.110 | 2010-06-15 12:55:02.110 |
| b'2010-07-07T12:23:50.110000' | 38.970549 | 22.999667 | 2010-07-07T12:23:50.110000 | 2010-07-07 12:23:50.110 | 2010-07-07 12:23:50.110 |
| b'2010-07-07T13:28:50.120000' | 53.589420 | 21.799833 | 2010-07-07T13:28:50.120000 | 2010-07-07 13:28:50.120 | 2010-07-07 13:28:50.120 |
Both these are much cleaner and faster due to pandas’ optimisation. We can now set one of these as the index
df.set_index('datetime', inplace=True)
df.head()
| max_len | ltime | time | other_datetime | |
|---|---|---|---|---|
| datetime | ||||
| 2010-06-01 13:00:14.120 | 27.022617 | 13.600000 | 2010-06-01T13:00:14.120000 | 2010-06-01 13:00:14.120 |
| 2010-06-01 12:58:02.120 | 36.208097 | 8.400000 | 2010-06-01T12:58:02.120000 | 2010-06-01 12:58:02.120 |
| 2010-06-15 12:55:02.110 | 62.932898 | 24.199833 | 2010-06-15T12:55:02.110000 | 2010-06-15 12:55:02.110 |
| 2010-07-07 12:23:50.110 | 38.970549 | 22.999667 | 2010-07-07T12:23:50.110000 | 2010-07-07 12:23:50.110 |
| 2010-07-07 13:28:50.120 | 53.589420 | 21.799833 | 2010-07-07T13:28:50.120000 | 2010-07-07 13:28:50.120 |
Now that there are official datetime objects on the index we can start operating based on the time of the frame
l_bins = df.groupby([df.index.year, df.index.month])
print(len(l_bins))
54
Here we have used the groupby command to take the 'max_len' column, called as a dictionary key, and create bins for our data to sit in according to year and then month.
The object l_bins has mean, max, std etc. attributes in the same way as the numpy arrays we handled the other day.
agg_spicules = df.groupby([df.index.year, df.index.month]).agg({'max_len': [np.mean, np.std]})
agg_spicules
| max_len | |||
|---|---|---|---|
| mean | std | ||
| datetime | datetime | ||
| 2010 | 6 | 42.054537 | 18.655367 |
| 7 | 36.717821 | 10.618364 | |
| 8 | 41.311295 | 5.440305 | |
| 9 | 34.696942 | 6.979722 | |
| 10 | 38.709587 | 3.391356 | |
| 11 | 45.177555 | 10.337633 | |
| 12 | 40.924916 | 11.664923 | |
| 2011 | 1 | 41.170836 | 13.310975 |
| 2 | 38.385196 | 10.294977 | |
| 3 | 37.007258 | 9.966492 | |
| 4 | 45.966302 | 9.281308 | |
| 5 | 39.049844 | 12.832214 | |
| 7 | 45.736577 | 12.569426 | |
| 8 | 42.089144 | 6.505276 | |
| 9 | 37.181781 | 2.942115 | |
| 10 | 45.276066 | 5.148206 | |
| 11 | 39.070391 | 5.866478 | |
| 12 | 34.882456 | 5.405979 | |
| 2012 | 1 | 50.059810 | 4.531475 |
| 2 | 32.477849 | 10.022291 | |
| 3 | 39.154133 | 12.585824 | |
| 4 | 32.305885 | 8.614694 | |
| 5 | 31.951032 | 8.301316 | |
| 6 | 30.973616 | 4.185172 | |
| 7 | 28.897303 | NaN | |
| 8 | 30.068358 | 7.679454 | |
| 9 | 36.644022 | 6.678510 | |
| 10 | 39.539804 | 6.273834 | |
| 11 | 36.201343 | 5.908986 | |
| 12 | 35.001790 | 7.305525 | |
| 2013 | 1 | 45.718231 | 6.730764 |
| 2 | 33.958883 | 3.328555 | |
| 3 | 44.252989 | NaN | |
| 4 | 41.490083 | 8.630605 | |
| 5 | 38.047579 | 5.048431 | |
| 6 | 53.229354 | 13.288040 | |
| 7 | 44.728946 | 9.625425 | |
| 8 | 33.382734 | 10.699844 | |
| 9 | 37.055785 | 5.729928 | |
| 10 | 31.258302 | 3.339021 | |
| 11 | 28.063602 | 7.889644 | |
| 12 | 32.474516 | 7.797334 | |
| 2014 | 1 | 42.680747 | 5.005861 |
| 2 | 26.620170 | 3.093437 | |
| 3 | 25.922509 | 5.225323 | |
| 4 | 31.924611 | 15.910663 | |
| 5 | 27.203932 | 5.172536 | |
| 6 | 30.948541 | 8.333880 | |
| 7 | 38.049466 | 10.603654 | |
| 8 | 33.752406 | 5.246553 | |
| 9 | 32.567724 | 7.447101 | |
| 10 | 39.904318 | 3.560158 | |
| 11 | 36.937597 | 4.900183 | |
| 12 | 40.789644 | 7.838396 | |
Now we have all this data we can build a lovely bargraph with error bars and wonderful things like that.
Remember, these pandas objects have functions associated with them, and one of them is a plot command.
agg_spicules.max_len['std']
datetime datetime
2010 6 18.655367
7 10.618364
8 5.440305
9 6.979722
10 3.391356
11 10.337633
12 11.664923
2011 1 13.310975
2 10.294977
3 9.966492
4 9.281308
5 12.832214
7 12.569426
8 6.505276
9 2.942115
10 5.148206
11 5.866478
12 5.405979
2012 1 4.531475
2 10.022291
3 12.585824
4 8.614694
5 8.301316
6 4.185172
7 NaN
8 7.679454
9 6.678510
10 6.273834
11 5.908986
12 7.305525
2013 1 6.730764
2 3.328555
3 NaN
4 8.630605
5 5.048431
6 13.288040
7 9.625425
8 10.699844
9 5.729928
10 3.339021
11 7.889644
12 7.797334
2014 1 5.005861
2 3.093437
3 5.225323
4 15.910663
5 5.172536
6 8.333880
7 10.603654
8 5.246553
9 7.447101
10 3.560158
11 4.900183
12 7.838396
Name: std, dtype: float64
fig, ax = plt.subplots(figsize=(16,10))
fig.autofmt_xdate()
std_err = agg_spicules.max_len['std']
agg_spicules.max_len['mean'].plot(kind='bar', ax=ax, yerr=std_err, grid=False, legend=False)
plt.show()
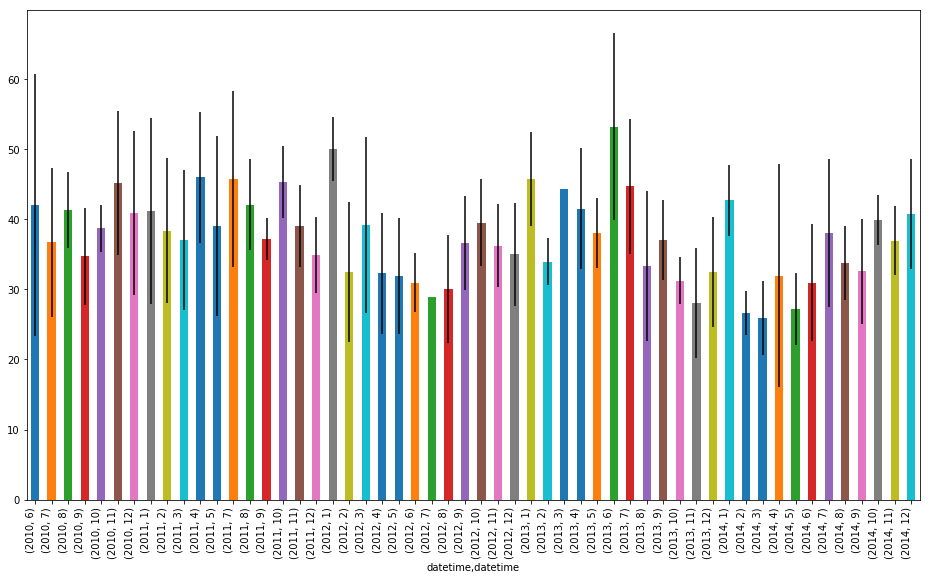
Note that the date on the x-axis is a little messed up we can fix with fig.autofmt_xdate()
How do the lifetimes change?
Now that we have the plot for the maximum length, now make a bar graph of the lifetimes of the features.
Exoplanet Data
Now, to all the astronomers out there, let us process some real data. We have some txt files containing the timeseries data from a recent paper. Can you process the data and show us the planet?
HINT: You'll need to treat this data slightly differently. The date here is in Julian Day so you will need to use these docs to convert it to a sensible datetime object, before you make the DataFrame.
import pandas as pd
import numpy as np
ep_data = np.loadtxt('data/XO1_wl_transit_FLUX.txt')
---------------------------------------------------------------------------
OSError Traceback (most recent call last)
<ipython-input-28-9af143cb8fd6> in <module>()
1 import numpy as np
----> 2 ep_data = np.loadtxt('data/XO1_wl_transit_FLUX.txt')
/opt/miniconda/envs/stfc/lib/python3.6/site-packages/numpy/lib/npyio.py in loadtxt(fname, dtype, comments, delimiter, converters, skiprows, usecols, unpack, ndmin, encoding)
924 fname = str(fname)
925 if _is_string_like(fname):
--> 926 fh = np.lib._datasource.open(fname, 'rt', encoding=encoding)
927 fencoding = getattr(fh, 'encoding', 'latin1')
928 fh = iter(fh)
/opt/miniconda/envs/stfc/lib/python3.6/site-packages/numpy/lib/_datasource.py in open(path, mode, destpath, encoding, newline)
260
261 ds = DataSource(destpath)
--> 262 return ds.open(path, mode, encoding=encoding, newline=newline)
263
264
/opt/miniconda/envs/stfc/lib/python3.6/site-packages/numpy/lib/_datasource.py in open(self, path, mode, encoding, newline)
616 encoding=encoding, newline=newline)
617 else:
--> 618 raise IOError("%s not found." % path)
619
620
OSError: data/XO1_wl_transit_FLUX.txt not found.
ep_dict = {'flux':ep_data[:, 1],
'err_flux':ep_data[:, 2]}
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-29-d45090fc219d> in <module>()
----> 1 ep_dict = {'flux':ep_data[:, 1],
2 'err_flux':ep_data[:, 2]}
NameError: name 'ep_data' is not defined
ep_df = pd.DataFrame(data=ep_dict, index=ep_data[:,0])
ep_df.index = pd.to_datetime(ep_df.index)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-30-cd9c5ddfe9fb> in <module>()
----> 1 ep_df = pd.DataFrame(data=ep_dict, index=ep_data[:,0])
2 ep_df.index = pd.to_datetime(ep_df.index)
NameError: name 'ep_dict' is not defined
from astropy.time import Time
t = Time(ep_data[:, 0], format='jd')
UTC = t.datetime
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-31-9b7b9b5c029b> in <module>()
1 from astropy.time import Time
----> 2 t = Time(ep_data[:, 0], format='jd')
3 UTC = t.datetime
NameError: name 'ep_data' is not defined
ep_df.index = UTC
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-32-74bafffb0dea> in <module>()
----> 1 ep_df.index = UTC
NameError: name 'UTC' is not defined